- Published on
In today's digital age, every aspect of our daily life, from social networking to online shopping, banking to health care, is deeply intertwined with vast amounts of data. This data is stored, managed, and retrieved using databases. Databases are the unsung heroes of our digital world, working behind the scenes to ensure we get the right information at the right time.

1. What is a Database?
A database is a structured collection of data that can be easily accessed, managed, and updated. At its core, the primary function of a database is to store and retrieve data in an efficient and secure manner. Think of a database as a digital library where instead of books, you store data in structured formats.
Roles of Databases:
- Information Storage: Databases serve as the primary medium to store vast amounts of data systematically.
- Quick Retrieval: They enable quick and efficient retrieval of data, which aids in real-time decision-making.
- Data Security: Databases come with features that prevent unauthorized access and breaches.
- Consistency and Integrity: Databases ensure data remains consistent across applications and that relations between data remain intact.
- Support for Business Operations: They serve as the backbone for a multitude of applications, be it e-commerce platforms, banking systems, or health record management systems.
Centralized vs. Decentralized Databases
Centralized Database:
- Definition: A centralized database is stored and maintained in one location. All the users and applications access this single database from different locations.
- Advantages:
- Easier data management and maintenance.
- Centralized backup and recovery.
- Consistency in data.
- Disadvantages:
- A single point of failure.
- Can experience network congestion.
- Scalability can become an issue with growth.
Decentralized Database:
- Definition: A decentralized database is distributed across several devices in different locations. Each device holds a part or a replica of the total database.
- Advantages:
- Enhanced reliability as there's no single point of failure.
- Local users can access data faster.
- Better scalability as systems can be added incrementally.
- Disadvantages:
- Complex data management and maintenance.
- Data integrity can become a challenge.
| Feature | Centralized Database | Decentralized Database |
|---|---|---|
| Location | Single location | Multiple locations |
| Data Access | Might experience congestion | Localized faster access |
| Reliability | Single point of failure | Higher reliability |
| Scalability | Can be challenging | Easier with incremental adds |
| Maintenance | Easier management | Complex management |
2. What is Structured Query Language (SQL)?
Structured Query Language, popularly known as SQL, is a domain-specific language used to manage and manipulate relational databases. SQL allows users to insert, update, delete, and retrieve data from a database, as well as define and manage database structures.
Table: Basic Functions of SQL
| Function | Description |
|---|---|
| Data Query | Retrieve specific data from a database using SELECT statements. |
| Data Update | Modify data in the database using INSERT, UPDATE, or DELETE statements. |
| Data Definition | These SQL commands are used for creating, modifying, and dropping the structure of database objects. The commands are CREATE, ALTER, DROP, RENAME, and TRUNCATE. |
| Data Control | Grant or revoke user permissions using GRANT and REVOKE commands. |
| Transaction Control | Ensure data integrity during operations using COMMIT, ROLLBACK, etc. |
Overview of SQL:
- Procedural vs. Non-Procedural Language: SQL is non-procedural, meaning it defines what you want to do rather than how to do it. Instead of detailing out every step, in SQL, you specify the result you want, and the database software figures out the best way to achieve that result.
- Standardization: Although there are variations of SQL depending on the database system (like T-SQL for Microsoft SQL Server or PL/SQL for Oracle), the core SQL commands are standardized by the American National Standards Institute (ANSI). This ensures some level of consistency across different database systems.
- Database Interaction: SQL interfaces with databases through a combination of data definition commands (e.g., CREATE, ALTER) and data manipulation commands (e.g., SELECT, INSERT).
- Query Optimization: SQL databases often come with a 'query optimizer' that determines the most efficient way to execute a query, ensuring quick retrieval or modification of data.

SQL as a Universal Language for Databases:
While there are various database management systems (DBMS) with their nuances and features, SQL serves as a unifying language, ensuring that users with SQL knowledge can interact with different relational databases.
Key Points on SQL's Universality:
- Cross-Platform: SQL can be used with different DBMS and on various operating systems, making it versatile for developers and administrators.
- Widespread Adoption: Since its inception in the 1970s, SQL has been adopted as the primary language for relational databases by leading DBMS providers.
- Robustness: SQL offers a wide range of functions, from simple data retrieval tasks to complex data analytics and transformations.
- Community & Support: Given its long history and widespread adoption, there's a vast community of SQL professionals and extensive documentation available, which aids in troubleshooting and learning.
Table : Evolution of Databases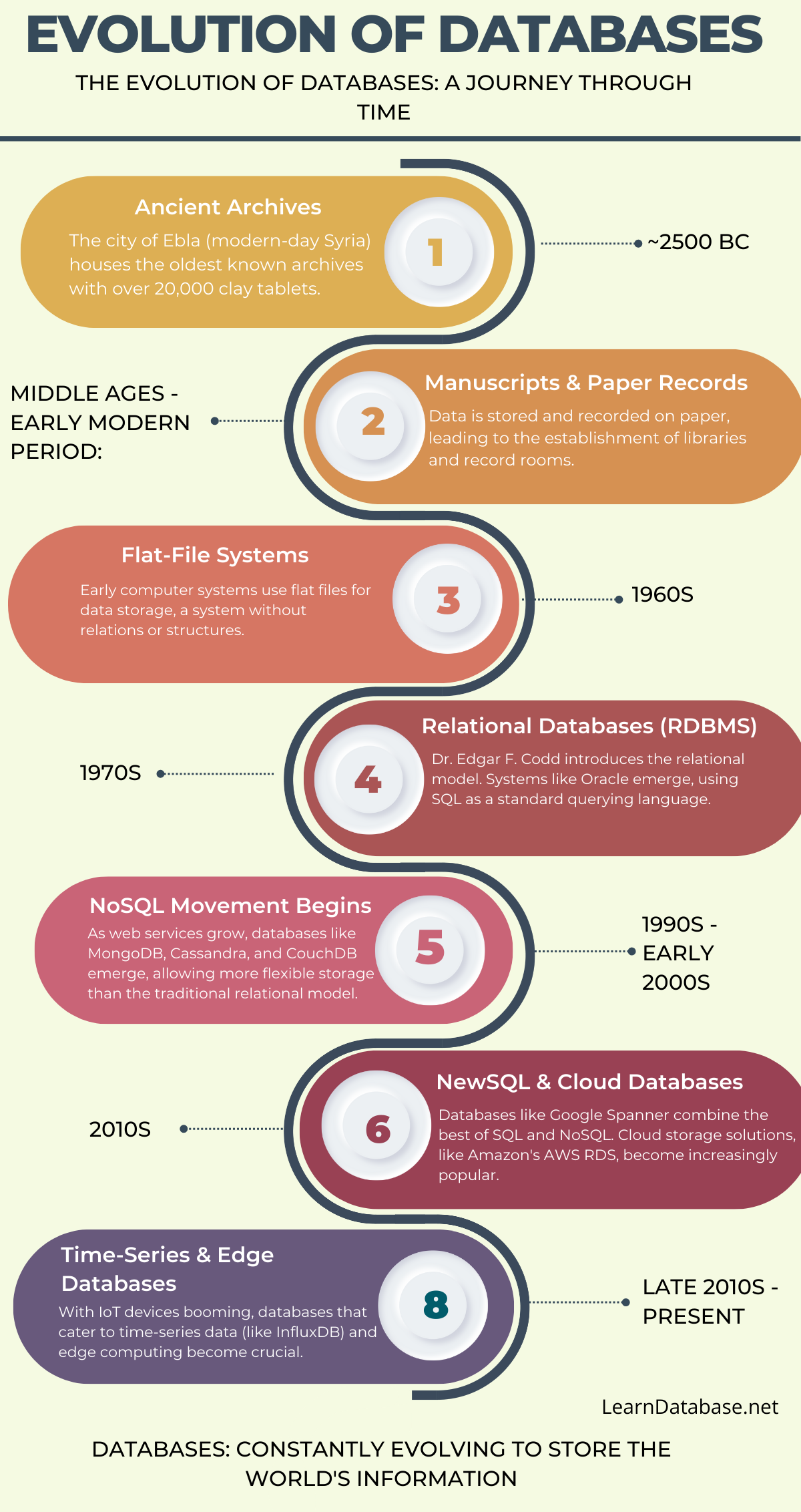
3. Types of Databases
In today's digital landscape, databases play a pivotal role in storing vast amounts of data generated by applications, websites, IoT devices, and more. As the nature and scale of data have evolved, so have the types of databases to cater to different needs. Let's see the primary categories:
Relational Databases (RDBMS):
Relational Databases Management Systems (RDBMS) are based on the relational model introduced by E.F. Codd. The data in RDBMS is structured in tables, and relationships between data items are expressed by means of tables.
Key Features:
- Tables: Data is organized in tables with rows and columns. Each row represents a record and each column represents an attribute of the data.
- Primary & Foreign Keys: Used to establish relations and ensure data integrity.
- SQL: Standardized language for querying and manipulating data.
Popular RDBMS: MySQL, PostgreSQL, Oracle, Microsoft SQL Server.
NoSQL Databases:
NoSQL databases are designed to allow for data storage and retrieval beyond the traditional tabular relations used in RDBMS. They're particularly suited for unstructured or semi-structured data.
Types of NoSQL Databases:
- Document-Based: Store data in a document-like format (typically JSON). E.g., MongoDB.
- Column-Based: Store data in columns rather than rows. E.g., Cassandra.
- Key-Value Stores: Use a hash table where a unique key points to a specific record. E.g., Redis.
- Object Stores: Store data in the form of objects. E.g., ObjectDB.
In-Memory Databases (IMDB):
These databases primarily rely on the system's main memory (RAM) for data storage rather than traditional disk drives, offering rapid data access.
Key Features:
- Speed: Accessing data in RAM is much faster than from a disk.
- Volatility: Being memory-based, there's a risk of data loss in case of system failure, though many IMDBs incorporate persistence methods.
- Use Cases: Real-time analytics, caching layers, and applications requiring high-speed processing.
Popular IMDBs: Redis (when configured as an in-memory store), SAP HANA, MemSQL.
Graph Databases:
Designed for data whose relations are well represented as a graph and have interconnected elements with an undetermined number of relations between them.
Key Features:
- Nodes & Edges: Data entities are represented as nodes, and the relationships between them are represented as edges.
- Traversal: They allow for easy and fast data traversals, making them ideal for social networks, recommendation engines, etc.
- Flexibility: Can easily incorporate new types of relationships or adapt to changing data schemas.
Popular Graph Databases: Neo4j, OrientDB, ArangoDB.

Table: Overview of Database Types
| Type | Characteristics | Examples |
|---|---|---|
| Relational | Table-based, SQL, Data Integrity | MySQL, PostgreSQL |
| NoSQL | Flexible schemas, Scalability, Varied Data Models | MongoDB, Cassandra, Redis |
| In-Memory | High speed, RAM-based, Volatile | Redis, SAP HANA |
| Graph | Nodes & Edges, Traversal, Flexible Relationships | Neo4j, ArangoDB |
4. Miscellaneous Databases
Hierarchical Databases:
- Description: Data is organized in a tree-like structure with a single root to which all other data is linked. Relationships between data are represented as parent-child connections.
- Key Features: Tree-like structure, Single parent node.
- Examples: IBM Information Management System (IMS).
- Description: Data is organized in a tree-like structure with a single root to which all other data is linked. Relationships between data are represented as parent-child connections.
Network Databases:
- Description: Similar to hierarchical databases but with a key difference: records can have multiple parent and child records.
- Key Features: Multiple parent nodes, network structure.
- Examples: Integrated Data Store (IDMS).
- Description: Similar to hierarchical databases but with a key difference: records can have multiple parent and child records.
Distributed Databases:
- Description: Databases that are distributed across multiple computers, possibly across multiple locations. The data may be replicated or partitioned across the nodes.
- Key Features: Data distribution across multiple nodes, data replication or partitioning.
- Examples: Apache Cassandra, Google Spanner.
- Description: Databases that are distributed across multiple computers, possibly across multiple locations. The data may be replicated or partitioned across the nodes.
OLAP Databases:
- Description: OLAP (Online Analytical Processing) databases are optimized for complex query processing and allow for complex analytical and ad-hoc queries.
- Key Features: Complex query processing, analytical operations.
- Examples: Microsoft Analysis Services, SAP BW.
- Description: OLAP (Online Analytical Processing) databases are optimized for complex query processing and allow for complex analytical and ad-hoc queries.
Time Series Databases:
- Description: Databases optimized for handling time-series data, i.e., data indexed by time.
- Key Features: Time indexing, optimized for time-series data.
- Examples: InfluxDB, TimescaleDB.
- Description: Databases optimized for handling time-series data, i.e., data indexed by time.
Object-Oriented Databases:
- Description: Databases that store data in the form of objects, as in object-oriented programming.
- Key Features: Object-based storage, methods and attributes.
- Examples: ObjectDB, db4o.
- Description: Databases that store data in the form of objects, as in object-oriented programming.
XML Databases:
- Description: Databases designed to store, query, and manipulate XML data.
- Key Features: XML data storage, XPath or XQuery for querying.
- Examples: BaseX, eXist-db.
- Description: Databases designed to store, query, and manipulate XML data.
JSON Databases:
- Description: Databases designed to store, query, and manipulate JSON data.
- Key Features: JSON data storage, JSON based querying.
- Examples: Couchbase, MongoDB.
- Description: Databases designed to store, query, and manipulate JSON data.
Note: It is essential to understand that the database landscape is continually evolving. The above classifications cover most commonly used database types, but there are other specialized databases designed for very specific use cases. Also, some databases may fall into multiple categories, as they offer features of more than one type of database. For instance, Couchbase and MongoDB are both document-based NoSQL databases but also provide features to store, query, and manipulate JSON data, classifying them as JSON databases as well.
5. Relational Databases vs. NoSQL Databases
Navigating the database landscape requires an understanding of the nuanced differences between traditional Relational Databases and the newer NoSQL Databases. While both serve the primary function of storing data, their approaches, structures and use cases vary significantly.
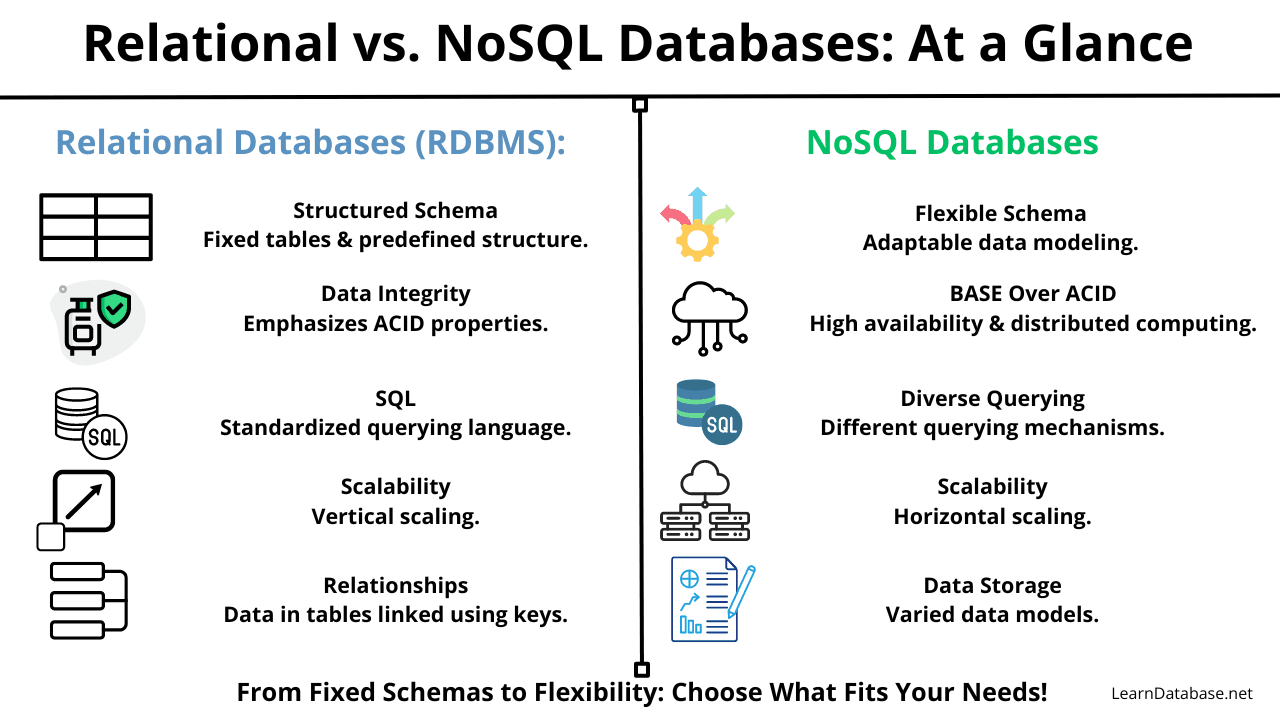
Characteristics of Relational Databases (RDBMS):
- Structured Schema: Data is stored in predefined tables with a fixed structure. Altering the schema often requires a significant effort.
- Data Integrity: Emphasizes ACID properties (Atomicity, Consistency, Isolation, Durability) to ensure reliable transactions.
- SQL: Uses SQL (Structured Query Language) for data definition, manipulation, and querying. This standardization ensures consistent querying capabilities.
- Scalability: Typically scales vertically, meaning you'd often scale by adding more power (CPU, RAM) to an existing machine.
- Relationships: Data is stored in separate tables and linked using keys, facilitating complex queries and joins.
Characteristics of NoSQL Databases:
- Flexible Schema: NoSQL databases offer flexibility in data modeling. This is particularly beneficial for applications with evolving schemas.
- BASE Over ACID: Prefers BASE properties (Basically Available, Soft state, Eventually consistent) which allows for high availability and distributed computing at the potential expense of strict consistency.
- Diverse Querying: Depending on the type of NoSQL database (document, columnar, key-value, graph), the querying mechanism can vary.
- Scalability: Designed to scale out by distributing the database across many servers. This horizontal scaling allows for increased capacity.
- Data Storage: Different types focus on different data models, from JSON-like documents, and wide-column stores, to key-value pairs or graph-oriented structures.
When to Choose Each Type:
- Choose Relational Databases (RDBMS) When:
- You need structured data with defined schemas.
- Data integrity and ACID compliance are paramount.
- Complex queries and joins are frequently used.
- Examples: Traditional business systems, ERP systems, and any system that demands complex transactions and relationships.
- Choose NoSQL Databases When:
- You have an evolving schema or a schema-less dataset.
- You require horizontal scalability.
- Rapid development is necessary, and flexibility is favored over strict consistency.
- Examples: Real-time analytics, mobile applications, social networks, and content management systems.
Table: Comparison of RDBMS and NoSQL Databases
| Criteria | Relational Databases | NoSQL Databases |
|---|---|---|
| Schema | Fixed and structured | Flexible and adaptable |
| Transactions | ACID compliance | BASE properties |
| Query Language | SQL | Varies (e.g., MongoDB uses its own BSON format) |
| Scalability | Vertical | Horizontal |
| Use Cases | Complex queries, Defined relationships | High scalability, Rapid development |
6. Advanced Database Design
The Process of Normalization
Normalization is a systematic approach to decomposing tables to eliminate data redundancy and undesirable characteristics like insertion, update, and deletion anomalies.
Goals of Normalization:
- Minimize data redundancy.
- Minimize data restructuring.
- Enforce referential integrity.
Stages of Normalization:
| Form | Purpose |
|---|---|
| 1NF | Ensure each column contains atomic (indivisible) values, and there are no repeating groups or arrays. |
| 2NF | Ensure all non-key attributes are fully functionally dependent on the primary key. |
| 3NF | Ensure all attributes are functionally dependent only on the primary key. |
| BCNF | Address any anomalies resulting from functional dependencies. |
Beyond BCNF, there are 4NF and 5NF, but they're less commonly used in most practical applications.
Data Indexing and Optimization
An index in a database resembles an index in a book – it lets you find the desired data without scanning every row in a table, which can be very time-consuming.
Advantages of Indexing:
- Speeds up data retrieval operations.
- Can enforce unique values in columns.
However, bear in mind:
- Indexes can slow down the speed of write operations (INSERT, UPDATE, DELETE).
- They consume additional disk space.
Types of Indexing:
| Type | Description |
|---|---|
| Single-level | An index file with pointers to the actual data block. |
| Multi-level | A hierarchical structure with multiple index levels, enhancing search speed. |
| Clustered | Rearranges the physical order of data in the database to match the index. |
| Non-clustered | Doesn't alter the physical order of data, but creates a completely separate object. |
Scaling Strategies: Sharding, Replication, Partitioning
As data grows, so does the need for databases to handle increased loads and maintain performance. This is where scaling comes in.
1. Sharding: Sharding involves breaking up your database into smaller, more manageable pieces, and distributing them across a range of storage resources.
- Pros:
- Can drastically improve performance by reducing the load on a single database server.
- Allows for horizontal scaling.
- Cons:
- Complexity in managing and maintaining multiple shards.
- Cross-shard transactions can be challenging.
2. Replication: Replication involves creating copies of your database, so you have a backup in case one fails and to distribute the query load.
- Types of Replication:
- Master-Slave Replication: All write operations are performed on the master, and reads can be distributed among slaves.
- Master-Master Replication: All nodes can handle both read and write operations.
- Pros:
- Provides data redundancy.
- Distributes query load, thereby enhancing performance.
- Cons:
- Might lead to data inconsistency if not managed correctly.
3. Partitioning: Partitioning divides a database into smaller, more manageable pieces, but all these pieces remain within a single instance of the database.
- Types:
- Horizontal Partitioning: Rows of a table are divided into smaller groups.
- Vertical Partitioning: Columns of a table are divided, and they are stored in different tables.
- Pros:
- Makes certain types of queries faster.
- Facilitates better management of data, especially in large tables.
- Cons:
- Queries that don't align with the partitioning strategy can be slow.
While each of these strategies has its own set of advantages, the best approach often involves a combination tailored to specific database needs.
7. Conclusion
Adapting to Coming Changes
Our digital world is changing fast due to quick advancements in technology. AI, serverless computing, and quantum computing are some of the big changes happening. These changes will also affect databases, making them able to handle bigger, more complicated, and dynamic data. It is very important to stay flexible and be ready to accept these changes.
The Significance of Continuous Learning in Database Management
Why Continuous Learning is Vital:
- Rapidly Changing Tech Landscape: The pace at which database technology is advancing mandates constant learning.
- Security: New threats emerge daily. Staying updated helps in building robust and secure databases.
- Efficiency: As businesses grow, understanding how to scale and optimize databases becomes essential.
- Career Advancement: For professionals in the field, continuous learning can open doors to higher responsibilities and roles.
A true database professional never stops learning. Join forums, attend conferences, and participate in workshops. Dive into online courses or get certified. The field is dynamic, and to stay relevant, continuous learning is the key.